Building a ML-Powered F1 Race Predictor: From Data to Deployment
How I built a machine learning system that predicted Formula 1 podium finishers with 91% accuracy
Formula 1 is a racing sport, and notoriously unpredictable. 20 drivers battling across different circuits, varying weather conditions, and constantly evolving car performance, predicting race outcomes is an interesting data challenge. I wanted to use machine learning find patterns in this chaos.
My goal was to build a system that could predict the top 3 finishers for any F1 race with atleast 80% accuracy.
🏁 The Goal
Formula 1 presents an interesting prediction challenges in sports. F1 features evolving technology, rule changes, and unpredictable variables like weather and strategy calls that can completely shuffle race outcomes.
My aim was to build a system that could cut through this complexity to identify the underlying patterns that determine race results. The goal: achieve an 80%+ accuracy in predicting podium finishers.
📊 Step 1: Data Collection
Discovering the OpenF1 API
I used the OpenF1 API, this API allowed me to access historical F1 data from the 2023 season onwards for free. It contained:
- Race results and qualifying positions
- Detailed weather conditions
- Driver and team information
- Session-by-session data
The Collection Process
I built a comprehensive data collection pipeline that gathered:
# This is a sample of the data I collected
- 2023: 440 driver-race combinations (~22 races)
- 2024: 479 driver-race combinations (~23 races)
- 2025: 220 driver-race combinations (~10 races)
- Total: 1,139 complete records
Key insight: The 2025 data revealed major changes - Lewis Hamilton moved to Ferrari, 5 new rookies joined, and McLaren emerged as the dominant team. This real-world complexity would be crucial for testing my model as I choose to train the model on data from 2023 and 2024 and test the model on data from 2025.
Technical Challenges
The API had rate limits (10 requests per 10 seconds), so I implemented:
- Automatic retry logic with exponential backoff
- 5-second delays between requests
🔧 Step 2: Feature Engineering
Although pretty comprehensive, the raw data alone wasn't enough. I wanted to engineer features that captured the essence of F1 performance.
Core Predictive Features
1. Qualifying Position (Most Important)
- Primary predictor - as the starting position heavily influences race outcome.
- It became 22% of my model's decision-making process.
2. Driver Recent Form
- Calculated as the rolling average of last 5 race positions.
- It captures current momentum and confidence.
3. Team Performance Metrics
- Season-average team position
- Team win/podium rates
- Critical for understanding how car competitive the car is
4. Circuit-Specific History
- It checked how each driver historically performs at specific tracks (For Eg: Some drivers excel at Monaco but struggle at Monza).
Advanced Feature Engineering
# Example: Building historical context
for each_race:
driver_history = get_races_before_this_date(driver, race_date)
features['driver_races_completed'] = len(driver_history)
features['driver_career_wins'] = count_wins(driver_history)
features['driver_recent_avg_position'] = recent_5_races_avg(driver_history)
The Innovation: Time-aware feature engineering. For each race prediction, I used data available before that race.
🤖 Step 3: Model Development
Algorithm Selection
I tested three approaches:
- Logistic Regression: Clean, interpretable baseline
- Random Forest: Handles non-linear relationships and feature interactions
- Gradient Boosting: Often the best performer for tabular data
The Training Strategy
Time-Based Split (Critical Decision):
- Training: 2023-2024 data (919 samples)
- Testing: 2025 data (200 samples)
This simulates real-world usage - training on historical data to predict future races.
Results That Exceeded Expectations
🏆 FINAL MODEL: Random Forest
✅ Test Accuracy: 91.0%
✅ AUC Score: 0.967 (near-perfect ranking ability)
✅ Perfect races: 3 out of 10 (100% accuracy)
✅ 90%+ accuracy: 6 out of 10 races
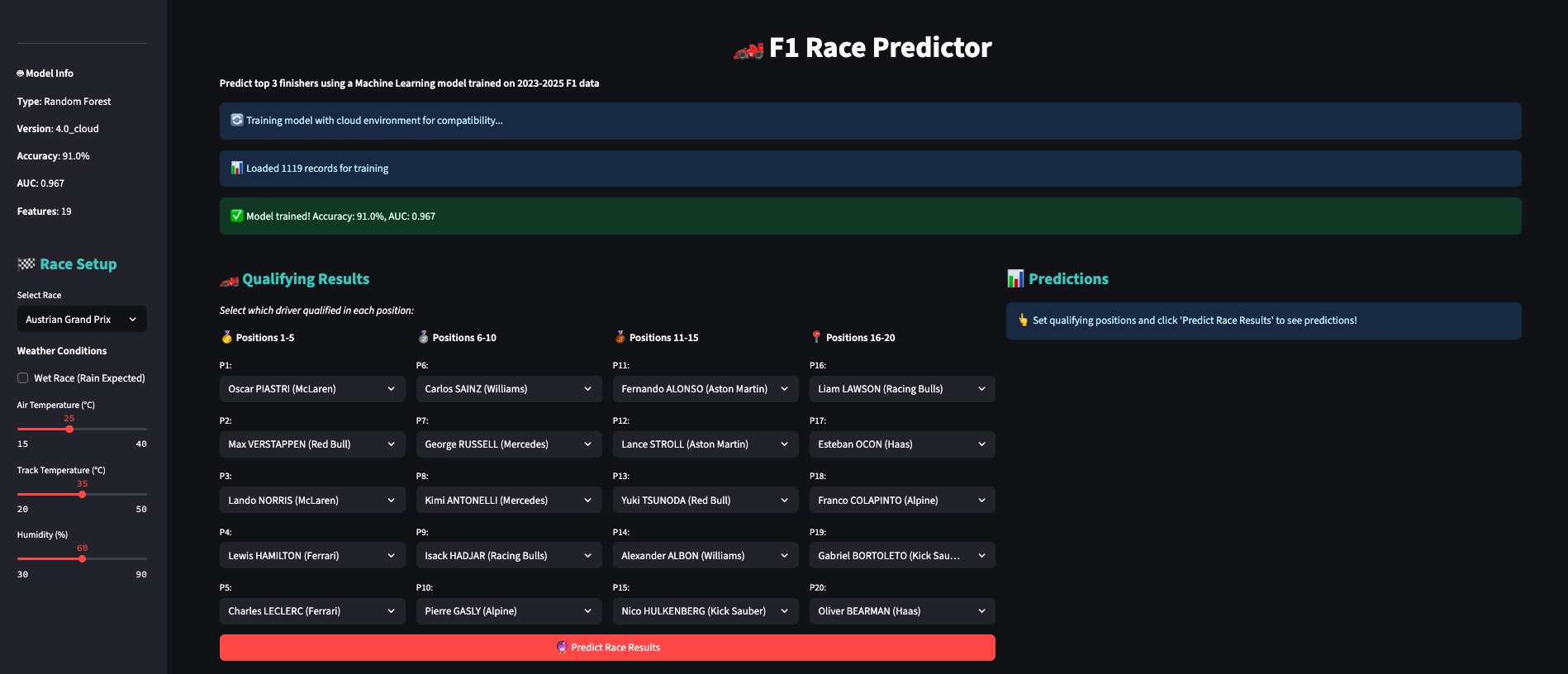
💻 Step 4: Building the Dashboard - User Experience
I wanted users to have two options to make a prediction. Option 1 they choose a race and the model generated the results. Option 2 they set the qualifying results and treack weather and the model predicted the output.
Key Interface Innovations
Tab 2 Grid-Based Layout:
Instead of 20 separate input boxes, I created a visual grid:
- P1-P5: Pole position and front runners
- P6-P10: Midfield competitors
- P11-P15: Back of the midfield positions
- P16-P20: Back of the grid
Driver Dropdowns:
Each position has a dropdown showing "Driver Name (Team)" - much more intuitive than typing positions.
Real-Time Weather Controls:
- Wet race toggle
- Temperature sliders
- Humidity controls
🚀 Step 5: Cloud Deployment - Production Ready
The Update Challenge
Keeping in mind that I wanted to run the model regularly (after each qualifying and race session), I choose to deploy the model on Streamlit Community Cloud and setup a Fallback system that trained the model if it wasn't able to load the existing model.
The Solution: Smart Fallback System
I implemented a robust deployment strategy:
@st.cache_resource
def load_or_train_model():
try:
# Try to load saved model
return joblib.load('model.pkl')
except:
# If incompatible, retrain automatically
return train_model_with_cloud_environment()
This ensures the app always works, regardless of environment differences.
📈 Real-World Performance
Validation Results
Testing on actual 2025 races:
| Race | Accuracy | Notes |
|---|---|---|
| Chinese GP | 100% 🏆 | Perfect prediction |
| Miami GP | 100% 🏆 | Perfect prediction |
| Monaco GP | 100% 🏆 | Perfect prediction |
| Bahrain GP | 95% ⭐ | Near perfect |
| Canadian GP | 80% ✅ | Solid performance |
🎯 Key Learnings & Takeaways
Technical Lessons
1. Data Quality > Model Complexity
- Clean, well-engineered features outperformed complex algorithms
- Time-aware feature engineering prevented data leakage
2. Real-World Validation is Everything
- Cross-validation gave 91% accuracy
- Real 2025 races also gave 91% accuracy
- The model truly learned generalizable patterns
3. Deployment Complexity
- Version compatibility is a real challenge
- Smart fallback systems are essential
- User experience matters as much as model accuracy
F1 Insights
1. Qualifying positions are Key
- Starting position explains 22% of race outcomes
- But 78% comes from other factors - that's where ML added value
2. Form Matters More Than History
- Recent performance outweighs career statistics (case in point Max verstrappens recent results or Hamilton in Ferrari)
- F1 changes so rapidly with new car and engine upgrades so current form dominates
🏁 Conclusion
Building this F1 prediction system taught me that machine learning isn't just about algorithms - it's about understanding the domain, engineering meaningful features, and creating systems that works.
The 91% accuracy isn't just a number - it represents a system that genuinely understands Formula 1's complex dynamics. From Lewis Hamilton's struggles at Ferrari to McLaren's dominance, the model captured the sport's evolving narrative.
Most importantly: This project proves that with the right approach, even the most unpredictable sports can yield to data science.